What is Test Automation? Types, Best Practice, Challenges, Benefits

Test automation is a critical pillar of the digital transformation ambitions of today’s enterprises. Automation testing is crucial for enterprise leaders. They should know why it is essential, the test automation framework, and the challenges in implementing it.
To succeed in the digital economy, it is not only necessary to roll out software faster, but it is equally essential to assure that the software is vetted for quality.
Studies estimate that by 2026, there will be a USD 49.9 billion worth of market for automation testing globally.
What is Test Automation?
Let’s begin with the basics. What is test automation? In simple terms, test automation is the automatic execution of software testing and management of test data, scripts, etc., without involving a human element.
It is widely used in enterprise application development initiatives worldwide to help accelerate the launch of apps or new features for existing apps. From startup firms to large businesses, an increasingly large number of enterprises have prioritized test automation in their digital maturity roadmap. Test engineers can use test automation tools to create scripts & test cases that can be reused an infinite number of times. And, this helps to automatically run testing activities for similar software functionality and reliability parameters.
The primary reason for migration from manual to automated testing is that companies save costs and efforts. Moreover, helps in the elimination of biased testing, which usually happens with manual testing practices.
SUGGESTED READ - The Evolution of Automation Testing
Types of Automated Testing
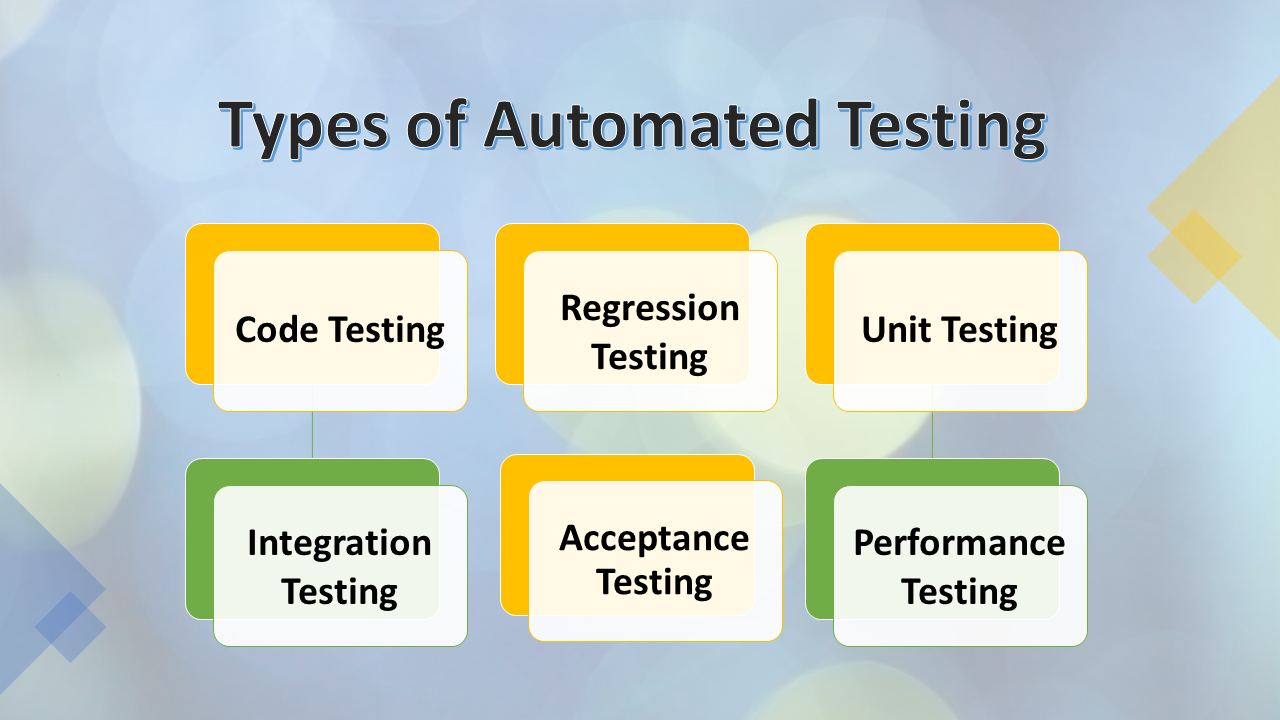
Similar to manual testing, Test automation also operates on a large scale and in a wide variety of ways, spanning a wide spectrum of end-to-end quality assurance processes.
Let us take a look at the various types of automated test initiatives followed by enterprises:
Code Testing
Code testing focuses on empowering developers or programmers to create and maintain sustainable and efficient coding practices. Firstly, it helps to check for vulnerable code snippets that may pose security risks. Secondly, it helps to correct formatting and style discrepancies before the code is checked out for execution or compiling.
Unit Testing
This enables quality assurance for a single piece of code or code unit representing a particular software module or functionality. It works well when dependencies with other modules, databases, external APIs, etc., are not in consideration. It also focuses on the code or code block alone and is usually very fast in execution.
Integration Testing
This helps ensure the quality of an application suite where different modules or sub-functions are integrated and constantly communicate via APIs and other messaging services. Automation of integration testing is complicated because there are a lot of dependencies that need to be mapped, test cases to be provisioned dynamically, and several resources and runtime environments to be set up depending on the number of integrated interfaces being tested.
Regression Testing
Regression Testing ensures that a software or code block offers uninterrupted functioning after any change has been made to it recently. Automating regression testing through a tool or platform with a user-friendly interface can significantly help save time and effort.
Performance Testing
It caters to ensuring that the application serves its purpose under any condition of scale or utilization volumes. For example, a website’s performance under extreme web traffic can be a perfect use case for performance testing. It is a key pillar that ensures a sustainable future for any digital application as it grows and accumulates transactional volumes significantly higher than in the initial days.
Acceptance Testing
Acceptance Testing deals with testing the scenarios for end-user acceptance of an application. This is one of the most critical areas of testing where you mimic actual end-user behavior in the testing stage. It also helps to ascertain whether the application can work without disruption under any stressed conditions. It is the final stage where developers and project managers can verify whether all requirements laid out during the initial requirement study phase have been met by the final product or feature being tested.
Do more with Test Automation
Discover more ways to add ‘low-code no-code‘ test automation in your workflows
Test Automation Framework Best Practices
A test automation framework enables better efficiency and fewer complications for enterprises in their QA initiatives.
And so, it is advisable to follow a framework with the below best practices:
- Identify the right criterion for automation
- Create scripts aligning to business requirements
- Involve all stakeholders from development to business users
- Wisely pick tools, test data, and allied resources that cater to business needs
- Extend coverage to all areas of development over time
- Prioritize the type of testing to be deployed across each module or functional unit
- Set standards for reporting
- Enable continuous feedback integration
Hence, this is important for improving the agility of QA practices for businesses. It allows them to roll out QA vetted software into the market for consumers and end-users faster.
Ready to Get Started?
Let our team experts walk you through how ACCELQ can assist you in achieving a true continuous testing automation
Challenges in Test Automation
Test automation is not without its fair share of challenges. It’s not always a walk-in-the-park situation where test engineers design and deploy the most suitable test automation approach to meet enterprise application quality needs.
Some of the most common challenges that plague test automation efforts at enterprises are:
Choosing the right testing approach:
It can be quite difficult to answer this question without first considering the following: (A) What is the complexity of your test automation framework or are they easy to maintain? (B) How can you measure test coverage accurately and systematically? (C) Did you consider looking into ways to reduce repetitive testing whenever possible? After answering these questions, it will be easier for you to choose the best testing approach.
High implementation costs upfront:
Test Automation is usually expensive at first. You need to analyze and plan the tests and create reusable functions or libraries before executing them. You also need to consider the licensing cost. Though these automation tools ensure a much higher ROI in the long run, the initial spending stands to be high.
Inefficient communication and collaboration between the development and testing team:
Not only this is a challenge in automation testing, but it is also the same with manual testing too. While working on test automation tools, the developers and testers need to interact to set testing objectives and targets. Hence it is important for everyone to be on the same page..
Selection of appropriate resources for test automation:
Automated testing requires technical skills to accurately craft and maintain a framework and test scripts, develop solutions, and fix bugs. Consequently, testers need a solid understanding of the framework’s design and implementation. Hence, they must possess both programming skills and solid test automation tools in order to meet these requirements.
SUGGESTED READ- Test Automation – Expectation Vs. Reality
Why software test automation is important?
Despite the several challenges with test automation, it is unwise not to implement it in your software development initiatives. This is because automated software testing brings in significantly high ROI in terms of long-term cost savings, faster time to market for software and features, better utilization of the technology workforce, and above all, a reliable and efficient application ecosystem.
In short, the best solution to mitigate the challenges in test automation is to use the right tool with the best architecture for seamless automation efficiency.
Try ACCELQ and achieve 3x productivity and over 70% savings.
Suggested Watch

![]()
![]()
![]()
Geosley Andrades
Director, Product Evangelist at ACCELQ.
Geosley is a Test Automation Evangelist and Community builder at ACCELQ. Being passionate about continuous learning, Geosley helps ACCELQ with innovative solutions to transform test automation to be simpler, more reliable, and sustainable for the real world.