





















LLMs in Software Testing: Use-Cases, Limits, & Risks in 2026

Software testing isn’t what it used to be. For years, teams have relied on structured scripts and repetitive logic, dependable but limited. Today, that model is breaking down. Software changes daily, release pipelines run nonstop, and QA teams are expected to keep pace without sacrificing quality.
That’s where LLMs in software testing come in. These models don’t just execute predefined steps; they understand, reason, and generate. Unlike older AI tools that depend on rigid rules, large language models in testing process understand natural language the way humans do. They read through requirements, analyze logs, and even interpret ambiguous user stories to produce actionable test logic.
Think of it this way: traditional automation does what it’s told. LLMs figure out what needs doing. They bridge the gap between human understanding and machine execution.
This article explores how QA teams are using LLMs to make testing smarter and faster, but also where these models hit their limits. You’ll see their core use cases, integration models, measurable benefits, and the real risks that come with adopting them too quickly.
- Key Use Cases of LLMs in QA
- Architectural Modes of LLM Integration in QA
- Quantitative Benefits and Measurable Impact
- Limitations of LLMs in Testing
- Risks of Using LLMs in QA and How to Reduce Them
- When and How to Adopt LLMs in Your QA Workflow
- The Future of LLMs in Software Testing
- Conclusion: The Balance Between Intelligence and Oversight
Key Use Cases of LLMs in QA
Let’s start with what these models actually do in practice. The most powerful use cases of LLMs in QA revolve around translating human intent into machine-readable testing actions. Here’s how teams are putting them to work:
Natural language to test specification
A tester can type something as simple as, “Verify that users can’t log in after three failed attempts,” and the LLM translates it into a structured, ready-to-run test case or behavior-driven development scenario. It’s like pair-programming with an assistant who instantly understands QA syntax.
Test case and scenario generation
LLMs in test automation can read through functional specs, Jira stories, or acceptance criteria, then produce both positive and negative test scenarios. They uncover gaps that manual writers might miss, helping QA teams reach higher coverage faster.
Test code and assertion scaffolding
Instead of starting from scratch, testers can prompt an LLM to generate the initial structure of automation scripts, complete with assertions and placeholder data. This makes script authoring far more efficient while maintaining code consistency across teams.
Maintenance and refactoring
Every QA team knows the pain of brittle tests. A small UI change can break dozens of scripts. LLMs can analyze what changed in the DOM or API schema and automatically refactor dependent test cases, reducing maintenance fatigue and accelerating continuous delivery.
Result summarization and anomaly detection
After test runs, LLMs can read logs, categorize errors, and summarize failures in plain English. They can flag patterns like recurring issues, missed dependencies, or performance drops, giving testers a clear path to AI-powered root cause analysis.
In essence, these models act like tireless copilots. They don’t replace the tester’s thinking, they extend it. They handle the repetitive groundwork, so humans can focus on strategy, validation, and exploratory depth.
Architectural Modes of LLM Integration in QA
How you bring LLMs into your QA ecosystem matters as much as what you use them for. There’s no one-size-fits-all model. The architecture depends on your goals, data sensitivity, and infrastructure maturity.
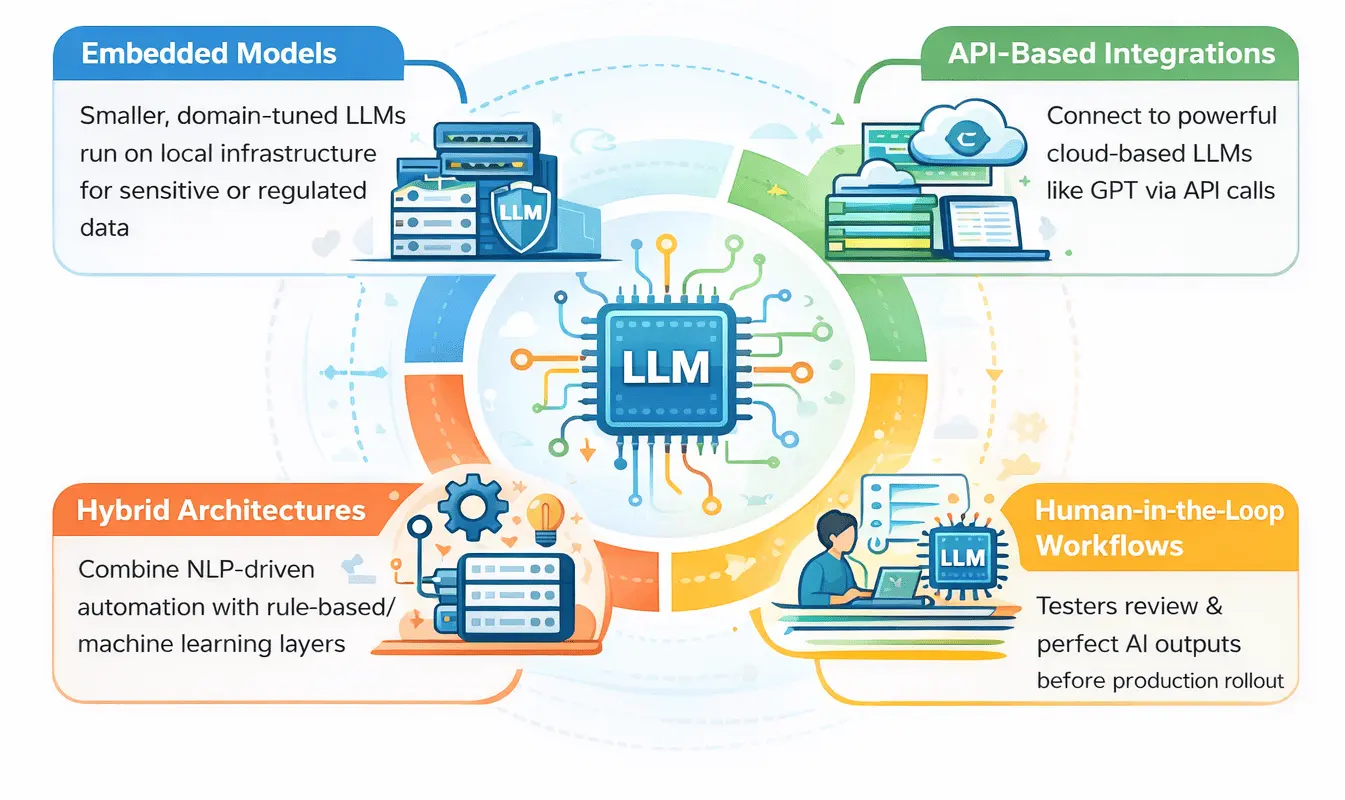
Embedded models
Some platforms integrate smaller, domain-tuned LLMs directly within their local environment. These on-prem models process test data without external dependencies, ideal for teams handling sensitive or regulated data.
API-based integrations
Others use API calls to connect with large cloud-based models like GPT or Claude. These provide more power and reasoning depth but require careful cost and latency management. For instance, API-based setups are great for generating tests from documentation or analyzing long error logs.
Hybrid architectures
A balanced approach pairs NLP test automation in software testing with rule-based or machine-learning layers. The LLM handles the creative reasoning, understanding language, mapping requirements, and generating scenarios, while heuristic systems ensure precision and determinism in execution. It’s creativity backed by structure.
Human-in-the-loop workflows
No matter how advanced LLMs become, QA validation remains a human responsibility. Many teams adopt a hybrid process where testers review, approve, and fine-tune AI outputs before pushing them to production. It keeps automation flexible without compromising trust.
This layered design is why LLM-powered test automation tools like ACCELQ Autopilot and other intelligent QA assistants are gaining traction. They integrate LLM intelligence without surrendering human control.
Quantitative Benefits and Measurable Impact
The benefits of LLMs in software testing aren’t abstract, they show up in metrics. When used effectively, teams report clear improvements in speed, coverage, and maintainability.
- Faster test creation: LLMs reduce script authoring time by 60–70%. Instead of days, new test suites can be generated in hours.
- Reduced maintenance: Automated refactoring cuts manual upkeep by up to 50%, freeing QA engineers from the constant patchwork of UI or API changes.
- Expanded coverage: By analyzing historical defects and edge conditions, LLMs identify additional scenarios, boosting coverage by roughly 30–35%.
- Lower costs: Despite compute expenses, the ROI stays positive due to reduced effort and faster release validation.
What this means in practice: QA teams can finally focus on strategy, designing quality pipelines and risk-based prioritization, while the LLM handles the mechanical grind of writing and updating tests.
Explore how AI is transforming QA.
Download our AI in Testing whitepaper to see real-world insights.
Limitations of LLMs in Testing
Every innovation has its trade-offs. Understanding the limitations of LLMs in testing helps avoid misplaced expectations.
Hallucination and inaccuracy
LLMs occasionally generate tests that sound right but are functionally incorrect. These “hallucinated tests” might include non-existent APIs or outdated workflows. Without validation, that leads to false confidence in coverage.
Prompt sensitivity
Small changes in phrasing can drastically alter output. “Generate login test” might produce something entirely different from “create authentication test.” Prompt consistency becomes a skill in itself, and a source of variability if unmanaged.
Model drift and brittleness
As models evolve through retraining, outputs may shift. A prompt that produced accurate test logic last quarter might behave differently after a model update. This makes version control and regression validation essential.
Latency and compute load
Handling long test data or large context windows can increase response times and infrastructure costs, especially for teams running thousands of tests across CI/CD pipelines.
The takeaway is simple: LLMs are powerful but imperfect. They need frameworks, constraints, and ongoing supervision, not blind trust.
Risks of Using LLMs in QA and How to Reduce Them?
Using LLMs in critical QA workflows comes with real risks. The good news: each one can be mitigated with practical guardrails.
Over-trusting AI-generated outputs
It’s tempting to assume LLM-generated tests are flawless. They’re not. Always include human review cycles and automated validation oracles before deployment.
Data privacy and leakage
Feeding sensitive data into prompts or logs risks exposing it to external systems. The safest approach is to sanitize all inputs and run models locally when handling proprietary information.
Bias and incomplete domain coverage
LLMs trained on general data might overlook edge cases specific to your domain. Financial transactions, healthcare logic, or regional compliance scenarios need fine-tuned models trained on domain-specific QA data.
Version control and compatibility issues
LLM vendors frequently update models, altering outputs unpredictably. Maintain your own version tracking for both prompts and generated artifacts, and test after every major upgrade.
Cost creep
Frequent API usage can inflate operational expenses. Setting quotas, caching common prompts, and optimizing context windows can keep costs under control.
With clear governance, audits, logs, and feedback loops, LLMs become reliable co-workers rather than risky black boxes.
Accelerate Your Testing ROI
Leverage AI-powered automation to reduce testing time by 70%.
When and How to Adopt LLMs in Your QA Workflow?
The smartest teams treat LLM adoption as an experiment, not a migration. The key is to start controlled, measure everything, and scale what works.
Start with low-risk pilots
Don’t begin with mission-critical apps. Test the waters on internal tools or low-impact modules. This gives room to learn, tweak prompts, and understand model behavior without production risk.
Build hybrid QA pipelines
Combine LLM-generated tests with human-curated suites. For instance, use LLMs for early-stage smoke or exploratory tests, while core regression stays manual or deterministic until confidence grows.
Run A/B experiments
Compare defect detection rates and turnaround times between AI-assisted and traditional pipelines. Quantify improvement before committing to full-scale adoption.
Invest in sustainable tooling
Modern LLM-powered test automation tools now come with integrated logging, cost controls, and prompt management dashboards. Platforms like ACCELQ Autopilot already use LLM orchestration under the hood to help teams scale intelligently.
Adoption isn’t about replacing your QA process, it’s about augmenting it, one layer at a time.
The Future of LLMs in Software Testing
The future of LLMs in software testing isn’t just about text. The next wave will combine language, visuals, and behavior into one unified model of understanding.
Multimodal reasoning
Future LLMs won’t just read code, they’ll “see” UI designs, detect visual regressions, and generate test logic based on screenshots or video recordings of user journeys.
Self-evolving test agents
AI agents will monitor test outcomes over time and evolve the test suite automatically. They’ll retire redundant tests, generate new ones for emerging risks, and optimize coverage dynamically.
Domain-specific and federated learning
Companies will train private LLMs on their QA datasets. These smaller, specialized models will outperform general-purpose ones in reliability, while ensuring data remains secure within enterprise boundaries.
Explainable testing intelligence
LLMs will soon provide reasons for every decision, explaining why a test failed or how it categorized an anomaly. That transparency will make AI-assisted QA auditable and compliant.
In short, the future isn’t about replacing QA engineers, it’s about giving them intelligent agents that grow with their systems.
Conclusion: The Balance Between Intelligence and Oversight
Here’s the reality: AI is not a magic wand. It’s a reasoning engine, one that can analyze patterns, interpret language, and generate tests faster than any human. But it still needs direction.
The benefits of LLMs in software testing are undeniable: faster cycles, broader coverage, and lower maintenance overhead. Yet, without proper oversight, those same models can introduce hallucinations, data leaks, and dependency risks.
The right path forward is balance. Start with pilots. Keep humans in the loop. Measure outcomes honestly. Over time, your QA process will evolve from rule-based execution to intelligent assurance, where human expertise and machine reasoning work as one.
The future of LLMs in software testing belongs to the teams who treat AI not as automation, but as collaboration.
Request a Demo and see how ACCELQ can transform your QA strategy.

Geosley Andrades
Director, Product Evangelist at ACCELQ
Geosley is a Test Automation Evangelist and Community builder at ACCELQ. Being passionate about continuous learning, Geosley helps ACCELQ with innovative solutions to transform test automation to be simpler, more reliable, and sustainable for the real world.

You Might Also Like:
 AI Agent for Defect Prediction: Is Your QA Strategy Future-Ready?
AI Agent for Defect Prediction: Is Your QA Strategy Future-Ready?
AI Agent for Defect Prediction: Is Your QA Strategy Future-Ready?
 AI-Driven Test Case Management for Maximizing Benefits
AI-Driven Test Case Management for Maximizing Benefits
AI-Driven Test Case Management for Maximizing Benefits
 AI Agents in Testing: Smarter Automation Beyond Chatbots & Assistants
AI Agents in Testing: Smarter Automation Beyond Chatbots & Assistants
